
模型介绍和初步认识
PLUS模型,(Patch-generating Land Use Simulation, PLUS)[1]是由中国地质大学(武汉)地理与信息工程学院&国家GIS工程技术研究中心的高性能空间计算智能实验室(HPSCIL)所开发的。
斑块生成土地利用变化模拟模型(Patch-generating Land Use Simulation, PLUS)核心包括两个模块,用地扩张分析策略(Land Expansion Analysis Strategy, LEAS)和基于多类随机斑块种子的 CA 模型(CA based on Multiple Random Seeds, CARS)。PLUS 模型在运算时,首先提取两期土地利用中发生用地类型转变的区域,基于随机森林算法(Random Forest Classification,RFC)针对新增加的部分 挖掘出不同驱动因子对于其影响的权重,继而生成每种地类的发展概率;然后基 于发展概率情况,将 CA 与斑块生成模拟策略相结合,来模拟未来土地利用情况。
用地扩张分析策略(Land Expansion Analysis Strategy, LEAS)
这个部分就是该策略提取两期土地利用变化间各类用地扩张的部分。并从增加部分中采样,采用随机森林算法逐一对各类土地利用扩张和驱动力的因素进行挖掘。获取各类用地的发展概率,及驱动因素对该时段各类用地扩张的贡献。
基于多类随机斑块种子的 CA 模型(CA based on Multiple Random Seeds, CARS)
这个部分就是该策略提取两期土地利用变化间各类用地扩张的部分。并从增加部分中采样,采用随机森林算法逐一对各类土地利用扩张和驱动力的因素进行挖掘。获取各类用地的发展概率,及驱动因素对该时段各类用地扩张的贡献。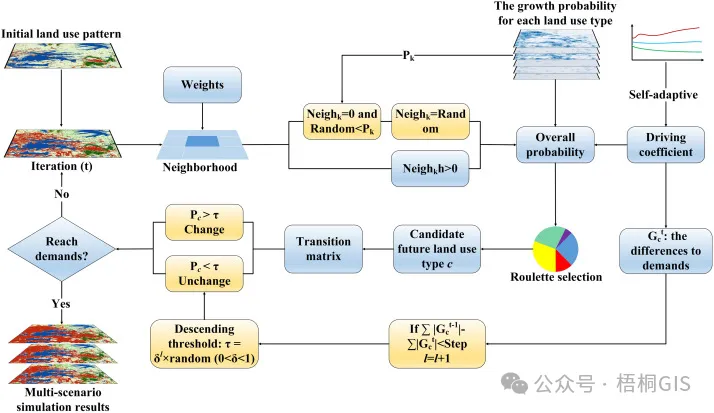
以上就是PLUS模型的主要内容,那么运行PLUS模型需要哪些部分呢?
(1) 土地利用数量预测(PLUS模型中集成了Markov chain)
(2) 利用PLUS模型提取两期土地利用变化间各类用地扩张的部分,采用随机森林算法逐一对各类土地利用扩张和驱动力的因素进行挖掘。获取各类用地的发展概率,及驱动因素对该时段各类用地扩张的贡献。(PLUS模型中的用地扩张分析策略(LEAS)部分)
(3) 将预测好的土地数量、各类用地的发展概率、领域权重、转移矩阵等等进行设定,运行模型就好了。
模型运行的数据准备以及参数设置
数据准备
想要模拟未来土地利用数据,需要一些数据,主要包括:2期土地利用数据(3期也行),众多你挑选的驱动因素数据。这些数据都有一定的要求:
(1) 所有数据必须是tif格式数据,且必须投影坐标系一致;
(2) 土地利用数据必须行列号一致!!驱动因素最好也统一);
(3) 土地利用数据据分类编号必须从1开始;
(4) 所有文件夹和数据命名格式需要为字母开头,不能以中文或数字开头;
(5) 模型安装包和相关数据必须是全英文路径。
这一步的思考
① 驱动因素是越多越好吗?是否存在多重共线性问题?
驱动因素应该并不是越多越好,合适的才是最好的。但是使用了随机森林模型算法的话,驱动因素多放一些也没有关系,因为随机森林模型可以很好的处理因子间空间自相关和多重共线性。
② 驱动因素是否应该归一化处理?
不需要,因为PLUS模型自动归一化
③ 是否有判断驱动因素组合最佳的方法?
模拟出的结果精度越高,说明组合越合理。
在TerrSet(也就是IDRISI Selval)的CA-Markov模型中,确实有判断驱动因素解释力的方式,克莱默V值。在欧定华老师(2020)的《景观生态安全格局规划理论、方法与应用》的案例研究中表明:景观格局变化潜力模拟平均准确率开始随组合驱动因子的个数增多而增加,当组合驱动因子个数达到一定数量时,模拟准确率呈下降趋势,组合驱动因子个数越多,其模拟准确性不一定更高。因此,欧定华老师选择驱动因素解释力高的因子进行不断组合,利用MLP-ANN对准确率进行测试,最终选择最佳组合。
为基于多类随机斑块种子的 CA 模型准备数据
用马尔可夫链预测未来土地需求
这一步的思考
利用CA进行土地利用变化空间模拟的时候,往往需要先预测区域土地利用变化总需求量和土地利用结构(这个过程被称为“自顶向下”)。
我喜欢称为数量预测,为什么需要数量预测呢?比如我想模拟一下2030年的土地利用格局,都是放在软件里跑,软件怎么知道运行到什么时候应该停下来,其实就是依据你在软件中所输入的未来的土地利用数量,当模型软件达到未来数量的时候,软件就停了。
预测区域土地利用变化总需求量和土地利用结构可以作为CA模型约束或者模型运行终止的关键条件。其作用就是使得CA的区域模拟能满足社会经济和人口发展的宏观规律,这就是“自顶向下”的区域约束。
这个数量预测的过程可以通过马尔科夫链(Markov chain)方法、系统动力学(system dynamics)方法、线性规划(Linearprogramming)方法等等等等,总之非常多,不同方法有不同方法的优势和劣势,但是这些方法有的可以称为土地利用预测,有的可以称为土地利用优化,预测和优化的区别在哪儿呢?预测一般是基于过去趋势和格局外推获取未来的土地数量,优化一般是,在一定约束条件下,把土地资源配置给效益较高的用地部门,以提高土地利用的总体效益,需要有确定优化目标和优化模型。好的,区别一张表进行解释:
当然你数量预测出来了其实还不够,你得知道空间分布在哪儿,这就是需要CA模型的运行,这得取决于CA的“自下而上”的核心模型,CA有四个基本要素:元胞、状态、领域和转换规则,最核心的部分就是定义转换规则,即土地发展的总概率(总概率包括:各类用地的发展概率、领域概率、领域权重、自适应惯性、转移矩阵。这以FLUS模型为例,PLUS模型也差不多)。一般来说,总概率最高的主导土地利用类型会被栅格单元优先分配,然后不同土地利用类型在数量的约束下,分配在其总概率高的空间位置上。
运行CARS模块
要运行这个模块,就必须充分了解页面中的各类参数的含义,以及如何设置科学的参数达到最佳的结果。
1、Neighborhood Size:邻域范围,默认为3(这个和领域权重有关)
2、Thread:并行线程数量,提高运行速度,此处设置为6(值越高,只要电脑够好,速度就够快)
3、Patch generation threshold: 递减阈值的衰减系数,范围0~1,值越高表示用地类型越不容易发生转换(我们此处设置为0.9,先设置高点儿)
4、Expansion coefficient: 扩散系数,随机斑块种子的概率,范围0~1,值越高表示越容易产生新的斑块,(按默认设置,之后再依据实际情况进行调整)
5、Percentage of seed:随机种子最大比例,范围0~1,值越小越紧凑,反之则越分散(按默认设置,之后再依据实际情况进行调整)
6、Devlopment zone:设置规划开发区(不涉及)
三大参数的确定
① Land Demands土地需求输入
这里使用马尔可夫链的预测结果,将其输入。
②Transtion Matrix转移矩阵设置
0表示不允许转换,1表示允许转换。比如2020年耕地能否变为2030年城镇用地。一般根据经验来填写,比如:耕地常常会变为城镇用地,而城镇用地很难变为其他土地等等。我们将该矩阵设置为
③Neighborhood Weights领域权重设置
方法一:经验设置
通过参考文献,自己的理解以及自己不断试验(哪个精度高用哪个),然后主观赋值0.01(参数范围 0~1,越接近1表示越容易产生新的斑块),耕地、林地、草地、灌木地、水域及人造地表邻域因子参数设定为 0.7、0.4、0.3、0.3、0.2、0.(参数范围 0~1,越接近1表示景观类型的扩张能力越强)。选择 Kappa 系数和 FOM(Figure of Merit) 系数进行模拟结果的精度评估,其中 Kappa 系数为 0~1。[4]
方法二:历史情境设置
根据前一阶段中土地扩展归一化值赋值(例如我们试验中用2010~2020的各类用地土地面积扩张去赋值。)
由于驱动因子同土地利用变化间关系的复杂性使得各用地类型的扩张强度较难直接计算,但各用地类型历史过程中的扩张规律却是对各自扩张能力的最好体现(王保盛等,2019)。文章分析了利用斑块面积(TA)和斑块数量(NP)作为领域权重测算的依据,表明斑块类型尺度上TA 的变化规律是对各用地类型扩张能力的定性表征,那么 TA 的变化量则可以用来定量表征各用地类型的扩张强度。利用公式:
其中,Wi是第i类土地类型领域权重,Tai为第i类土地利用扩张面积,TAmin为各类土地利用最小扩张面积,TAmax为各类土地利用最大扩张面积。即城区扩张面积-某个最小扩张面积/某个最大扩张面积-最小扩张面积
开始运行!Run
参考来源:梧桐GIS公众号


